LLM-as-a-Judge
LLM-as-a-Judge is an evaluator that uses an LLM to assess LLM outputs. It's particularly useful for evaluating text generation tasks or chatbots where there's no single correct answer.
The evaluator uses the gpt-3.5 model. To use LLM-as-a-Judge, you'll need to set your OpenAI API key in the settings. The key is saved locally and only sent to our servers for evaluation—it's not stored there.
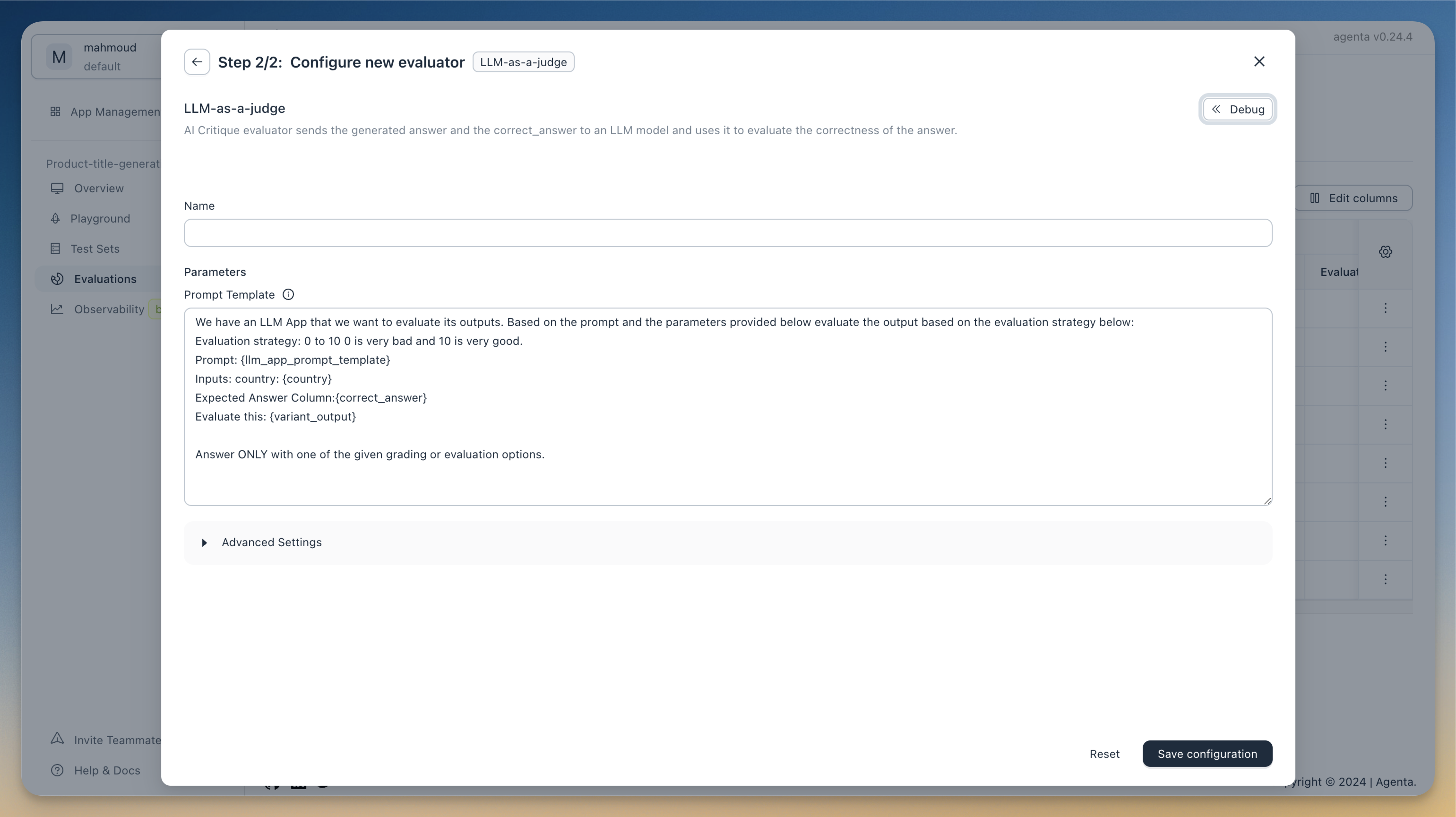
You can configure the prompt used for evaluation. This evaluator has access to the inputs, outputs, and reference answers.
Here is an example prompt:
We have an LLM App that we want to evaluate its outputs.
Based on the prompt and the parameters provided below evaluate the output based on the evaluation strategy below:
Evaluation strategy: 0 to 10 0 is very bad and 10 is very good.
Inputs: country: {country}
Expected Answer Column: {correct_answer}
Evaluate this: {variant_output}
Answer ONLY with one of the given grading or evaluation options.
The prompt has access to these variables:
correct_answer: the column with the reference answer in the test set. You can configure the name of this column underAdvanced Settingin the configuration modal.variant_output: the output of the llm application- The inputs to the LLM application, named as the variable name. For the default prompt (Capital expert), the input is
country